As part of The Year of Synthesis I decided to slightly open the door and have new stimuli enter my comfortable little bubble.
I reviewed the general news landscape and decided on the Financial Times as they seem mostly central and the once-a-week pace of the FT Weekend is right up my alley. At £35 for 3 months the FT Digital Edition seems reasonable and the cheapest way to access the FT Weekend so I went with that.
As someone who believes that nearly all news isn’t all that noteworthy or valuable, I still had a problem. Even the FT Weekend, without day-to-day drivel, has articles I’m just not interested in while I sip on my first hopeful Saturday morning coffee. And so many ads, why do I pay for this again?
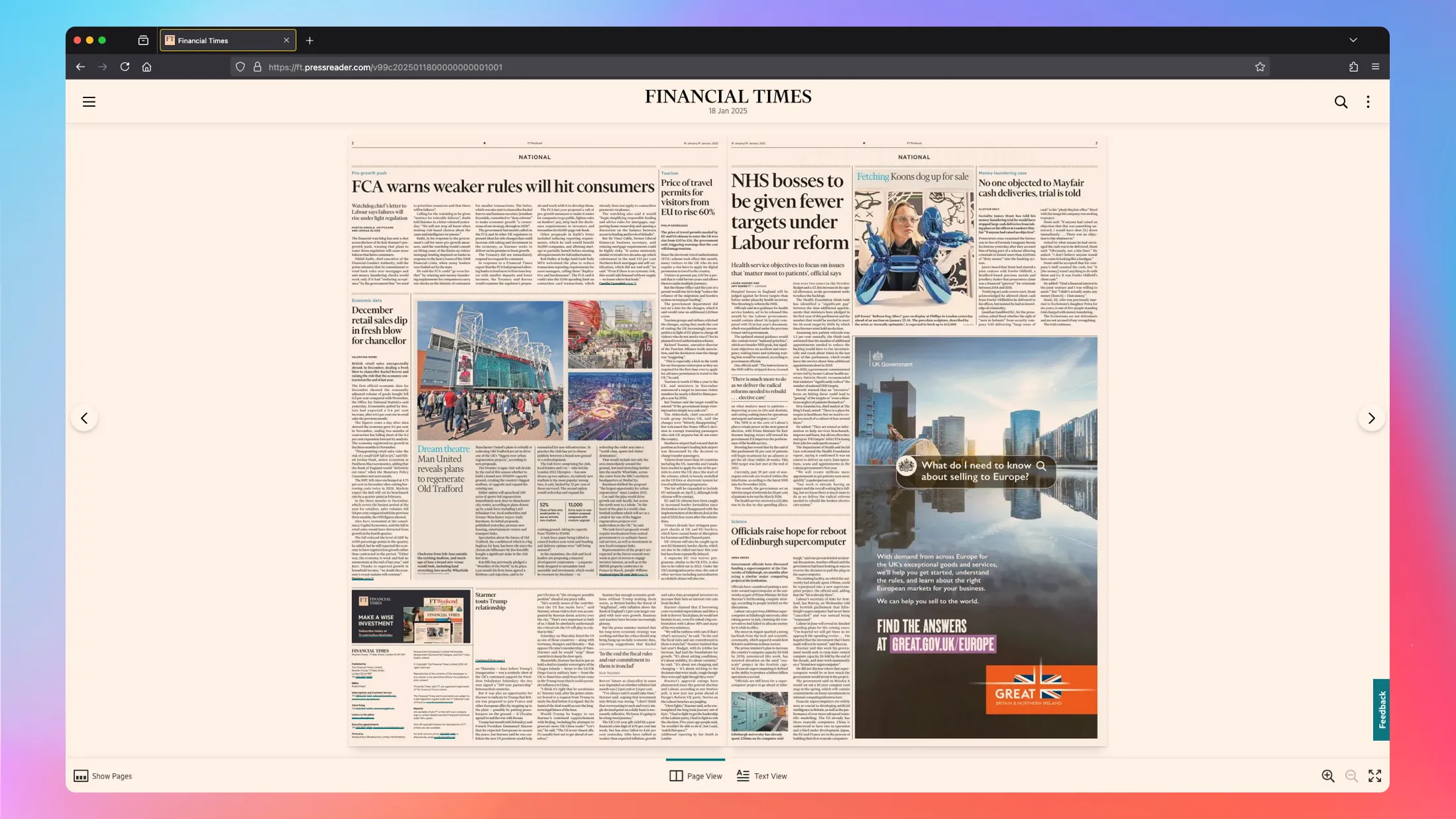
This may have been a showstopper for my “read the news” ambitions. But let’s see what we can do.
First, the format. The virtual newspaper from PressReader works well, but it has all the same ads you would get in the printed version. Boo. The other layout option “Text View”, is a lot more “digital first” in that it’s more of a normal website experience - with no ads. I’m in.
Now if I could just get rid of these articles on topics I don’t care about, something like this..
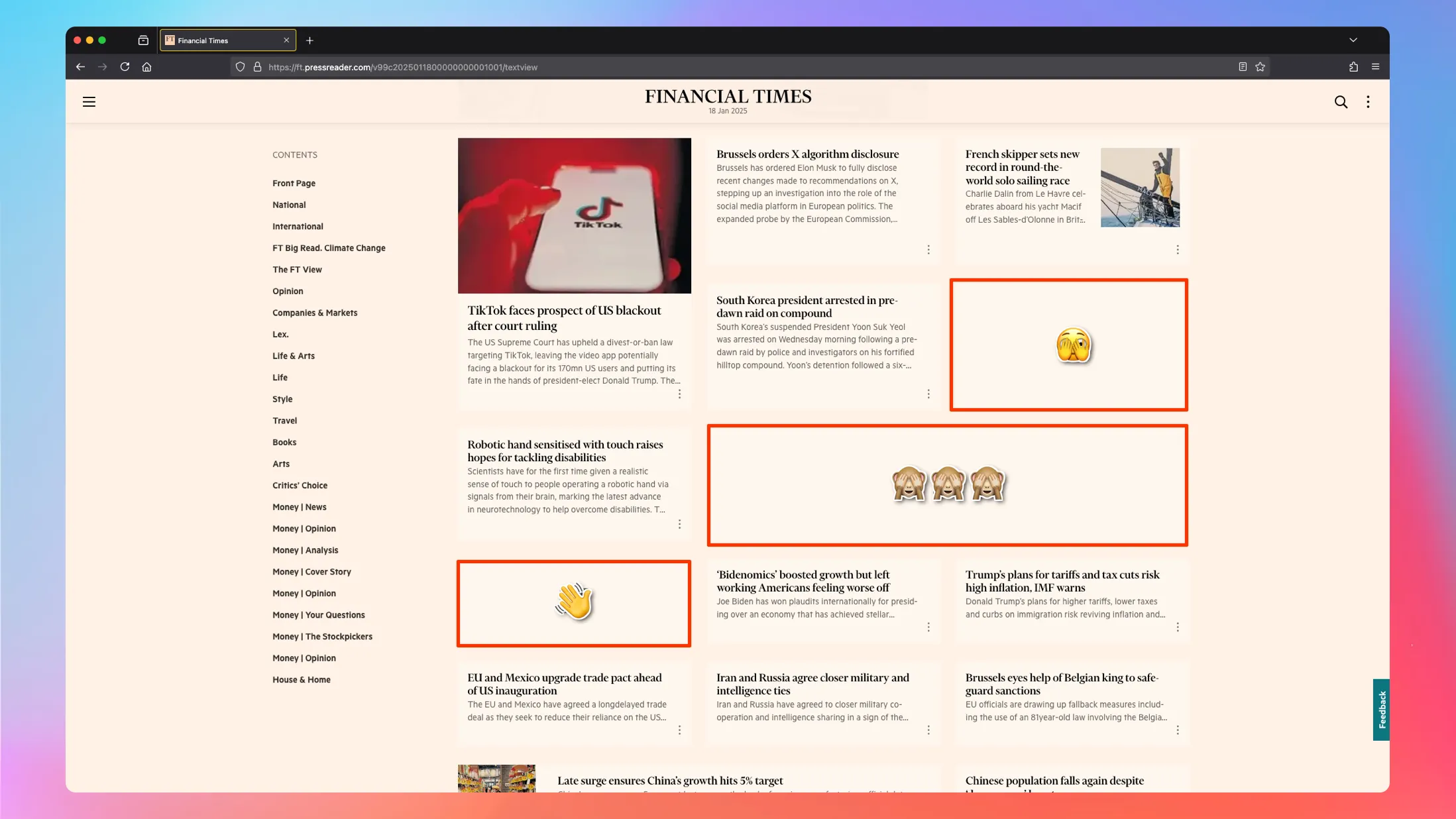
Yet another silly article on AI reminded me that in the age of AI, I can probably prompt this content-filtering problem out of existence.
I explored the code for PressReader’s “Text View” and saw it is a Single Page Application. That’s developer for lots of javascript making the page work in the browser. It reminded me of a similar problem I solved on Twitter a few years ago to hide some of the spammy content they shoved into my feed. Then I used a Chrome extension to go through all the shown tweets and hide some based on user settings - details for the curious.
Why not do the same thing here? Except, now the extension could be way smarter because with something like Ollama it is trivial to run a small AI model like llama3.2 3b locally and have it do the content tagging for me based on any incoming content. Imagine..
I can build that.
I don’t use Chrome anymore, because lol Google spyware. But with the help of Cline creating a Firefox extension is easy.
Download and install Ollama if you don’t have it already. Then open a terminal and type ollama run llama3.2 and it should pull and start running the model on your device.
You will also need ngrok installed to access the Ollama API running locally from a secure SSL website, such as PressReader. Installation is simple just follow their docs.
Start a static ngrok tunnel to Ollama with the command: ngrok http --url=your-static-ngrok-url.ngrok-free.app 11434 --host-header="localhost:11434"
Now, let’s make an extension.
Create a new directory for it somewhere, and then create the first manifest.json file which defines what the extension can do and access. Update with your ngrok tunnel URL.
{
"manifest_version": 2,
"name": "Jacobs AI Filter",
"version": "1.0",
"description": "Analyzes articles for AI-related content and blurs them",
"permissions": [
"https://your-static-ngrok-url.ngrok-free.app/api/generate",
"*://*.pressreader.com/*"
],
"browser_specific_settings": {
"gecko": {
"id": "[email protected]"
}
},
"background": {
"scripts": ["background.js"]
},
"content_scripts": [
{
"matches": ["*://*.pressreader.com/*"],
"js": ["content.js"]
}
]
}
Next up, create content.js, this file will handle reading everything on the website and blurring stuff we don’t want to see.
function isValidText(text) {
// Check if text is empty or just whitespace
if (!text || text.trim().length === 0) return false;
// Check if text is too short (less than 10 characters)
if (text.trim().length < 15) return false;
// Check for lorem ipsum patterns
const loremIpsumPatterns = [
/lorem\s+ipsum/i,
/dolor\s+sit\s+amet/i,
/consectetur/i,
/adipiscing\s+elit/i,
];
if (loremIpsumPatterns.some((pattern) => pattern.test(text))) return false;
// Check if text is mostly special characters or numbers
const alphaContent = text.replace(/[^a-zA-Z]/g, '').length;
const totalContent = text.trim().length;
if (alphaContent / totalContent < 0.3) return false; // Less than 30% letters
return true;
}
async function analyzeText(text) {
try {
if (!isValidText(text)) return false;
const response = await browser.runtime.sendMessage({
type: 'analyzeText',
text: text,
});
return response.shouldFilter;
} catch (error) {
return false;
}
}
function createBlurContainer(article) {
const existingContainer = article.querySelector('.blur-container');
const existingWarning = article.querySelector('.content-warning');
if (existingContainer) existingContainer.remove();
if (existingWarning) existingWarning.remove();
const container = document.createElement('div');
container.className = 'blur-container';
container.style.cssText = `
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background: inherit;
filter: blur(1px);
transition: filter 0.3s;
z-index: 1;
`;
const warning = document.createElement('div');
warning.className = 'content-warning';
warning.textContent = 'Analyzing content...';
warning.style.cssText = `
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
background: rgba(0, 0, 0, 0.7);
color: white;
padding: 10px 20px;
border-radius: 5px;
z-index: 2;
pointer-events: none;
`;
article.style.position = 'relative';
article.appendChild(container);
article.appendChild(warning);
return { container, warning };
}
function removeBlurElements(article) {
const container = article.querySelector('.blur-container');
const warning = article.querySelector('.content-warning');
if (container) container.remove();
if (warning) warning.remove();
}
async function processArticles() {
const articles = document.querySelectorAll('article');
for (const article of articles) {
if (article.hasAttribute('data-processed')) continue;
article.setAttribute('data-processed', 'true');
const { container, warning } = createBlurContainer(article);
const title = article.querySelector('.article-title')?.textContent || '';
const description = article.querySelector('.article-text')?.textContent || '';
const fullText = `${title} ${description}`;
const validText = isValidText(fullText);
try {
const shouldFilter = validText ? await analyzeText(fullText) : false;
if (shouldFilter) {
warning.textContent = ':)';
article.addEventListener('mouseenter', () => {
container.style.filter = 'none';
warning.style.opacity = '0';
});
article.addEventListener('mouseleave', () => {
container.style.filter = 'blur(5px)';
warning.style.opacity = '1';
});
} else {
removeBlurElements(article);
}
} catch (error) {
warning.textContent = 'Error analyzing content';
}
}
}
// Initial processing
processArticles();
// Watch for new content
const observer = new MutationObserver((mutations) => {
for (const mutation of mutations) {
if (mutation.addedNodes.length) {
processArticles();
break;
}
}
});
observer.observe(document.body, {
childList: true,
subtree: true,
});
Finally, create the AI magic in background.js. Update with your ngrok tunnel URL and define what content you want to filter in the AI prompt. Make sure to have it return “true” for something you don’t want to see, and “false” for things you are ok with.
async function analyzeText(textToAnalyze) {
try {
const response = await fetch('https://your-static-ngrok-url.ngrok-free.app/api/generate', {
method: 'POST',
body: JSON.stringify({
model: 'llama3.2',
prompt: `Analyze if this text is about AI or Large language model(s) or any kind of artificial intelligence. Only respond with "true" if it is, otherwise respond with "false" if it is not: "${textToAnalyze}"`,
stream: false,
}),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const data = await response.json();
const result = data.response.trim().toLowerCase() === 'true';
return result;
} catch (error) {
throw error;
}
}
browser.runtime.onMessage.addListener((message, sender) => {
if (message.type === 'analyzeText') {
return analyzeText(message.text)
.then((result) => ({ shouldFilter: result }))
.catch((error) => ({ shouldFilter: false, error: error.message }));
}
});
Obviously, in my example here I chose to filter out AI content, but your filter can be anything you like.
That’s it! Load your extension in Firefox and you should be mostly safe from everything you don’t want to see within your own news-content-bubble once more.
I’m very happy with how this extension turned out. On my M3 Max MacBook Pro it takes 2-3 seconds to review all articles on screen and it’s accurate about 90-95% of the time. Not bad for free.
You can also package your extension for distribution or as I have as unlisted so it’s always enabled without having to do anything when the browser reopens or the computer restarts.
Just don’t package and share your private ngrok tunnel URL, unless you want to donate your GPU to help moderate content for others.
Thanks for stopping by.